


Содержание
Перейти к:
https://doi.org/10.18599/grs.2025.3.22
Перейти к:
Скважинные имиджеры являются мощным инструментом для исследования сложнопостроенных коллекторов, предоставляя уникальную информацию о структурных и текстурных особенностях изучаемых пластов, в том числе информацию в масштабе кернового материала. Развитие методов обработки и интерпретации позволяет оптимизировать существующие подходы к оценке имиджей на качественном и количественном уровнях. Они также способствуют повышению эффективности и качества работы с имиджами за счёт новой пообъектной информации. В данной работе предлагается современная методика анализа имиджей, основанная на результатах обработки большого и уникального объёма накопленных данных с применением технологий машинного обучения. Разработанные алгоритмы позволяют автоматизировать процесс предобработки имиджей, а также процесс структурно-текстурной декомпозиции. Применение глубоких нейронных сетей обеспечило выделение целевых объектов с точностью более 90%, а алгоритмы компьютерного зрения позволили получить их количественную характеристику в виде оценки размеров, форм, ориентаций и топологий. Области применения предлагаемой методики включают в себя: седиментологический анализ (в частности, обнаружение тонких пропластков); дополнение к программам исследований сплошного и бокового керна; дополнение к программам исследований с помощью пластоиспытателя на кабеле (детальное описание особенностей коллекторов в интервалах, не охарактеризованных керном); дополнительная информация для обработки и интерпретации комплекса геологических и геофизических данных (моделирование пласта с использованием детерминированного подхода, критерии распределения для стохастического моделирования, определение петрофизических параметров с высокой степенью достоверности).
Коссов Г.А., Абашкин В.В., Егоров С.С., Макиенко Д.О., Гаева В.А. Новая методика текстурно-структурного анализа имиджей с помощью алгоритмов глубокого обучения. Георесурсы. 2025;27(3):209-220. https://doi.org/10.18599/grs.2025.3.22
Kossov G.A., Abashkin V.V., Egorov S.S., Makienko D.O., Gaeva V.A. A new state-of-the-art technique for textural and structural microimager data analysis using deep learning algorithms. Georesursy = Georesources. 2025;27(3):209-220. (In Russ.) https://doi.org/10.18599/grs.2025.3.22
Имидж, как один из методов расширенного комплекса геофизических исследований скважин (ГИС), позволяет визуализировать стенки скважины: получать своего рода «фотографии», которые на петрофизической диаграмме или планшете принимают вид развертки от 0 до 360 градусов. Имиджи – это продолжение развития такого направления ГИС, как наклонометрия. С постепенным увеличением количества электродов стало возможным описывать не только отдельные плоскостные границы, но и давать их морфологическую и текстурную характеристику. Следует отметить, что сегодня существует достаточно большое семейство приборов (имиджеров), которые обеспечивают получение имиджей. Например, у крупнейшей нефтесервисной компании Шлюмберже к таким приборам можно отнести FMI-HD, QGEO, QGEO Slim, TBEI, FMS, DOBMI, OBMI, UBI, MicroScope HD, TerraSphere, MicroScope и geoVISION. Подобное разнообразие имиджеров обусловлено необходимостью высокого качества данных в зависимости от сильно различающихся скважинных условий. Помимо компании Шлюмберже, линейкой имиджеров обладают другие международные (приборы STAR, STAR-HD, CBIL, StrataXaminer, EMI, XRMI, PixStar, COI, UMI, CMI) и отечественные (приборы МС, МС-С, АС) компании.
С точки зрения интерпретации имиджеры необходимо разделять по уровню исследования на микроимиджеры и макроимиджеры. Такое разделение обусловлено разрешающей способностью прибора и определяет детализацию и полноту проводимой интерпретации. Именно микроимиджеры позволяют получить максимальную информацию при исследовании сложнопостроенных терригенных и карбонатных коллекторов. Самым распространенным и проверенным временем микроимиджером является прибор FMI (Formation MicroImager). Микроимиджер FMI позволяет проводить высокоразрешающее сканирование стенок скважин, заполненных раствором на водной основе. Результатом такого сканирования является имидж сопротивления с осевым и азимутальным разрешением до 5 мм. Полученный имидж отображает характер напластования, структурные и текстурные особенности пластов-коллекторов и вмещающих пород. Интерпретация данных имиджеров находит самое широкое применение в структурной геологии, фациальном и седиментологическом анализах, а также может привлекаться для решения геомеханических задач. Особенно эффективен прибор для обработки тонкослоистости с выделением пластов мощностью от нескольких сантиметров, т.е. в масштабе исследования керна. Именно работа в масштабе исследования керна обуславливает необходимость повышенных трудовых затрат на обработку и интерпретацию, что, в свою очередь, увеличивает стоимость работы с имиджами для конечного пользователя.
Основополагающими и самыми трудоемкими задачами при обработке имиджей являются: увязка с данными ГИС, увязка с керновым материалом, трассирование и классификация объектов, структурно-текстурная декомпозиция. Ошибки и неточности при выполнении этих задач (во многом за счет человеческого фактора) могут нивелировать все преимущества микроуровня исследований, что критически скажется на результатах интерпретации при работе со сложнопостроенными коллекторами. Одной из наиболее частых проблем при работе с такими резервуарами является вынужденное упрощение геологических и петрофизических характеристик, используемых при моделировании месторождения. Это происходит как в силу аппаратных ограничений (конечное разрешение методов ГИС), так и физических: осуществлять бурение каждой скважины с выносом керна технологически и экономически нецелесообразно. Существующий качественный, а не количественный подход к анализу имиджей подтверждает вышесказанное. Сегодня для снижения неопределенности при работе со сложными коллекторами необходимы автоматические инструменты для интерпретации имиджей, которые как обеспечат пообъектный подход к описанию имиджей, так и дадут возможность их количественной структурно-текстурной обработки.
На основании статистики регистрации имиджей иностранными нефтесервисными компаниями за последние 25 лет работы в России было записано порядка 5 000 имиджей, что соответствует интервалу 1 500 000 метров (~300 м средний интервал записи). Если еще 5 лет назад на рынке имиджеров практически отсутствовали отечественные нефтесервисные компании, то в последнее время они начали активно развиваться и проводить большое количество работ (например, имиджеры производства ООО «Геофизтехника», г. Саратов). Грубая оценка рынка имиджей показывает, что каждый год он растёт в среднем на 400 единиц. Такие цифры говорят о том, что в России не осталось средних и крупных недропользователей, которые бы не обладали такими видами данных, как имиджи. Скважинные имиджеры активно применяются наряду с обязательным комплексом ГИС при освоении месторождений нефти и газа, в том числе на континентальном шельфе.
В то же время следует отметить, что у рынка имиджей остается большой потенциал роста, т.к. на данный момент отсутствуют автоматизированные инструменты обработки. Разработки новых методик в данной области особенно актуальны в связи с уходом с рынка иностранных нефтесервисных компаний, которые предоставляли услуги по анализу данных. Поэтому применение имиджей при комплексной интерпретации ГИС носит индивидуальный, а не массовый характер. С учетом большого количества накопленных архивных данных, описывающих различные геологические условия практически по всей территории России, становится возможным использовать алгоритмы искусственного интеллекта для автоматизации задач при работе с имиджами.
В литературе представлены единичные работы по созданию алгоритмов для решения отдельных проблем интерпретации имиджей (Li et al., 2016; Mohammad Faiq Adenan et al., 2023; Ponziani et al., 2013; Shafiabadi et al., 2021). Например, в существующих программных продуктах текстурный анализ основывается на алгоритмах SOM (self-organizing map, самоорганизующиеся карты Кохонена) (Kohonen, 2013), MRGC (multi resolution graph based clustering, многомерная кластеризация на графах) (Ye, Rabiller, 2000) и методике ручного выбора граничных значений по гистограмме распределения комплексного параметра имиджа (продукт Techlog PorTex). Как видно в первом и во втором случаях, подходы в большей степени представляют процесс кластеризации, а не комплексной количественной оценки. К сожалению, подробного описания этих инструментов в настоящее время в литературе не представлено, что усложняет их объективный анализ. По отзывам пользователей результаты не всегда находят применение на практике. Нередки рабочие процессы, основанные на применении традиционных алгоритмов компьютерного зрения и статистических приёмов. В статье (Mohammad Faiq Adenan et al., 2023) для решения задачи идентификации трещин применялись цифровые фильтры Габора (Gabor, 1946) и Canny (Canny, 1986), при этом пороговые значения были выбраны с помощью алгоритма Otsu (Otsu, 1975). В работе (Chang Li et al., 2020) использовался метод многоточечной статистики (multipoint statistics) (Tahmasebi, 2018) при обработке данных трещиноватых карбонатов для восстановления полноразмерного имиджа. Выделение каверн и трещин было выполнено с помощью алгоритма адаптивной бинаризации по Otsu. К общему недостатку таких методов можно отнести ограниченную точность, ручное конструирование признаков, их малую обобщающую способность и высокую чувствительность результатов обработки к шуму и изменению масштабов. Традиционные алгоритмы также зависят от качества фона и контрастности изображения. Ручной подбор параметров делает их трудоемкими и менее гибкими для настройки под конкретные задачи интерпретации данных FMI по сравнению с алгоритмами глубокого обучения. При этом классическое компьютерное зрение имеет свою ценность, особенно для случаев небольших наборов данных.
В литературе также представлены работы по применению алгоритмов искусственного интеллекта для обработки данных FMI. В статье (Fathi et al., n.d.) представлен рабочий процесс, основанный на классических инструментах машинного обучения для прогнозирования естественной трещиноватости. В работе выполнен широкий обзор методов классификации и регрессии: RandomForest (Rigatti, 2017), KNeighbors (Fix, 1985), DecisionTree (De Ville, 2013), XGB (Chen, Guestrin, 2016), ExtraTrees (Geurts et al., 2006), LogisticRegression (Walker, Duncan, 1967), BernoulliNB (McCallum, Nigam, 1998), GradientBoosting (Friedman, 2001), LinearSVC (Cortes, 1995), GaussianNB (John, Langley, 2013), SGD (Rosenblatt, 1958), MultinomialNB7 (Rennie et al., 2003), ElasticNetCV (Zou, Hastie, 2005), AdaBoost (Freund, Schapire, 1995), GradientBoosting, RidgeCV (Hilt, Seegrist, 1977), SGD, LassoLarsCV (Tibshirani, 1996). В выводах авторы показали, что наиболее лучших метрик (R2 и MSE) достиг метод KNeighbors. В статье (Kharitontseva et al., n.d.) показана идея использования данных FMI в качестве связующего звена между геологией и петрофизикой. С одной стороны, вертикальное разрешение 5 мм обеспечивает прямое сравнение керна и данных имиджеров, что помогает идентифицировать структурные и текстурно-геологические особенности коллектора. С другой стороны, принцип действия имиджеров основан на измерении физических свойств горной породы, например, электропроводности. Таким образом, имиджи можно сравнить с другими данными каротажа, в том числе для описания интервалов, в которых не проводился отбор керна.
При этом применение нейросетевых алгоритмов (в частности, глубоких нейронных сетей) обычно рассматривается в контексте решения частных задач интерпретации данных и не затрагивает комплексную обработку. Например, выделение трещин (Azim, 2021; Li et al., 2016; Shafiabadi et al., 2021) и восстановление полноразмерного имиджа. В работе (Qifeng Sun et al., n.d.) задача восстановления имиджа решается с помощью применения генеративных сетей с использованием U-net (Ronneberger et al., 2015). Авторы показали преимущества разработанной модели перед обычными сетями кодирования–декодирования по показателям SSIM, PSNR, MSE и FID (Sara et al., 2019).
В соответствии с вышесказанным цель настоящей работы состоит в разработке методики, которая позволит автоматизировать процесс предобработки имиджей, а также процесс структурно-текстурного анализа как на качественном, так и на количественном уровнях. Предлагаемая методика даст возможность ускорить и стандартизировать обработку, минимизировать субъективный вклад специалиста, повысить качество интерпретации и, как следствие, снизить затраты.
В связи с наличием значительного объема накопленных данных было принято решение в основе методики использовать алгоритмы глубокого обучения. В частности, были выбраны алгоритмы обучения с учителем: глубокие свёрточные нейронные сети. Обученные модели помогут быстро анализировать большие объемы информации, поступающие в режиме реального времени, что ускорит и упростит интерпретацию имиджей, а также минимизирует человеческий фактор. Отличительным преимуществом применения моделей глубокого обучения является их гибкость и возможность оперативного дообучения. Благодаря этому можно адаптировать модели для новых данных или изменяющихся условий (выполнить дообучение), снизить аппаратурную зависимость и обеспечить обработку данных соседних скважин.
В общем случае задачи обработки изображений свёрточными сетями можно разделить на:
Поскольку основная цель данной работы заключается в получении количественных характеристик имиджей, то необходимо с помощью нейронной сети выделять целевые объекты (маски), обеспечивая сохранение их формы, размеров и взаимного расположения. Это задача семантической сегментации с последующей оценкой полученных масок стандартными алгоритмами компьютерного зрения. Пример маски для задачи сегментации на 2 класса (фон и объекты) представлен на рис. 1 C.
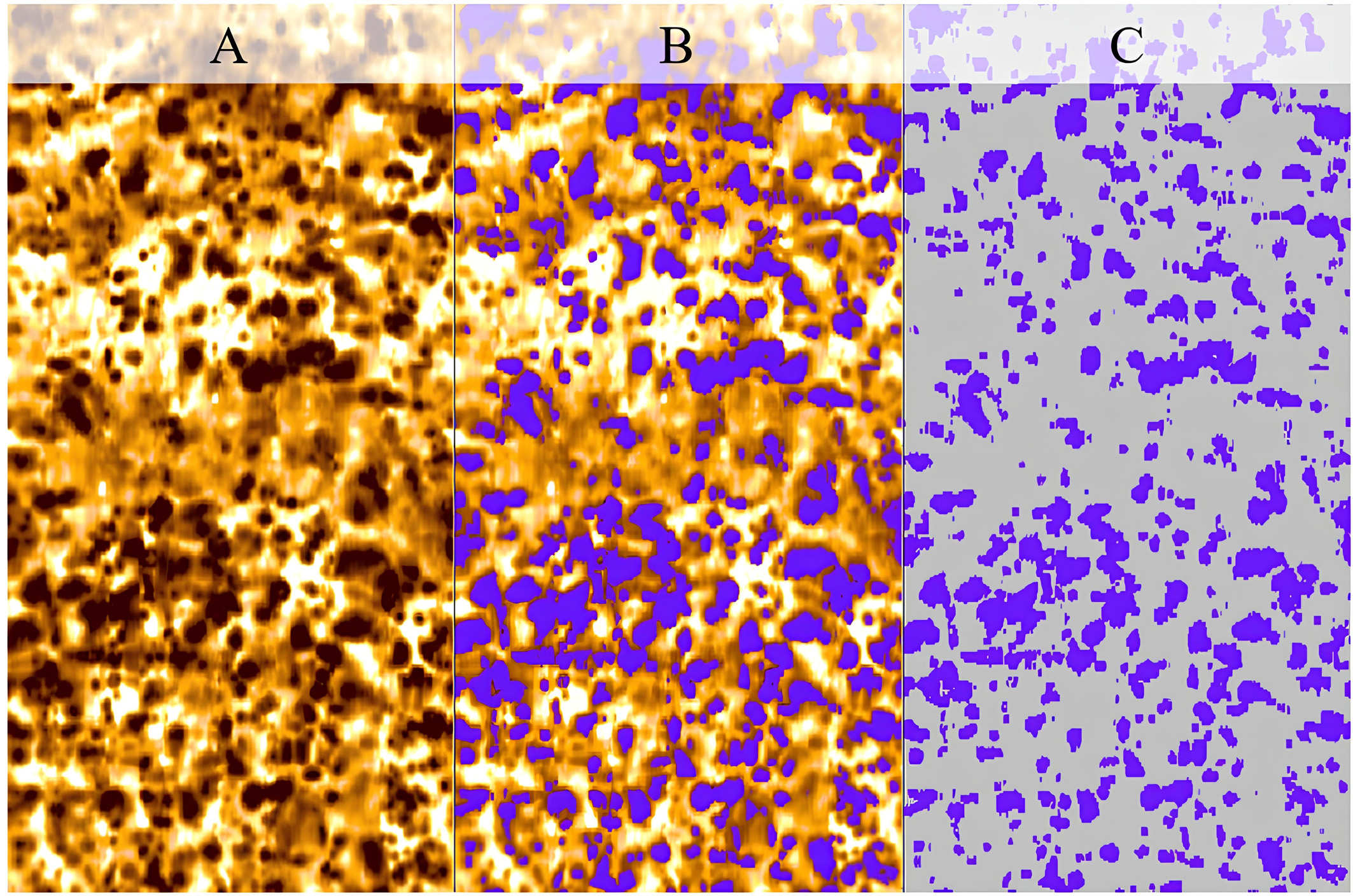
Рис. 1. Пример бинарной целевой маски для фрагмента изображения имиджа. Обозначения: A – имидж, B – имидж с наложенной маской, C – маска, на которой обозначены целевые (фиолетовый цвет) и фоновые объекты (серый цвет).
В отличие от классических цифровых изображений, где каждый пиксель отражает значение яркости или цвета, данные имиджей представляют собой матрицу (набор одномерных кривых) значений электропроводности пласта по окружности и вдоль глубины ствола. Такие данные часто имеют пропуски, шумы и варьирующийся по глубине шаг измерений, что осложняет их дальнейшую обработку. Первым этапом предобработки обычно служит нормализация: значения параметров приводятся к сопоставимому масштабу, что упрощает их сравнительный анализ и снижает влияние выбросов. Затем применяется фильтрация шумов с учётом специфики источника данных – могут использоваться адаптивные сглаживающие или медианные фильтры, а также продвинутые методы, учитывающие физическую природу сигналов. Важным шагом является интерполяция, особенно если данные поступали с разным шагом по глубине, содержат пропуски или различные артефакты при записи (обусловленные как внешними факторами, так и особенностями самого измерительного инструмента). После выполнения предобработки данные имиджей были размечены экспертом (рис. 1) и нарезаны на квадратные изображения размера 96х96 пикселей с некоторым шагом. Всего было размечено ~100 м данных, что дало порядка 3000 изображений. При этом были удалены маски, у которых площадь выделенных объектов составила менее 1% от всей площади. После этого датасет был поделен на тренировочный (90%), валидационный (5%) и тестовый (5%) наборы.
Для обработки данных была выбрана архитектура сверточной нейронной сети типа автоэнкодер, состоящая из сужающейся части (энкодера) и расширяющейся части (декодера) (рис. 2), которая хорошо зарекомендовала себя в решении задач семантической сегментации. Энкодер отвечает за извлечение информативных признаков из входных данных. Декодер восстанавливает пространственную структуру и исходное разрешение изображения (строит маску), используя полученные энкодером признаки. Энкодер и декодер соединены латентным признаковом пространством, которое содержит наиболее важные и низкоуровневые признаки. Непосредственно сами признаки извлекают повторяющиеся свёрточные блоки. Блоки в свою очередь содержат следующие процедуры: операции 2D свёртки (convolution), субдискретизации (pooling), пакетной нормализации (batch norm) и применение функции активации.
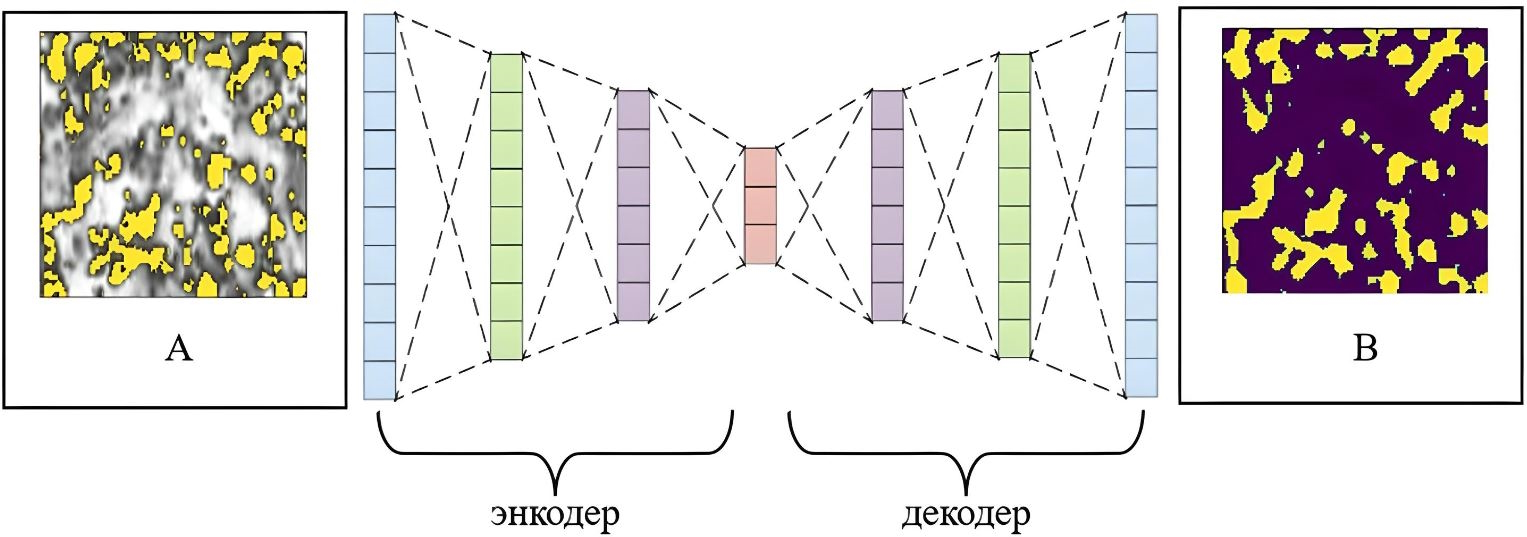
Рис. 2. U-подобная архитектура. Обозначения: A – входное изображение с наложенной маской, B – сегментированное изображение.
Одной из известных реализаций такой архитектуры является модель U-Net, изначально разработанная для сегментации медицинских томографических изображений (Ronneberger et al., 2015). U-Net за счёт симметричной архитектуры и механизма пропуска слоёв (skip connections) хорошо справляется с задачами, требующими точного локального выделения объектов. Объединяя карты активации из энкодера непосредственно с картами активации декодера соответствующего размера, сквозные слои передают подробную информацию с низких уровней к высоким по всей сети на этапе декодирования. Это помогает восстанавливать пространственные взаимосвязи, потерянные во время субдискретизации на этапе сжатия.
Однако качество сегментации, продемонстрированное U-Net на нашем наборе данных, оказалось неудовлетворительным. К тому же модель характеризуется высокой вычислительной сложностью и большим количеством настраиваемых параметров (порядка 34 525 058 настраиваемых параметров и 200 МБ места на жёстком диске для сохранения самой модели и обученных весов), что существенно увеличивает объем ресурсов для её обучения. Визуализация свёрточных фильтров обученной сети показала, что многие веса представляют собой случайный шум, тогда как эффект переобучения уже возник: ошибка на тренировочных данных падала, а ошибка на валидации возрастала.
С целью уменьшения явления переобучения и повышения эффективности процесса сегментации нами была разработана облегченная модель, превосходящая U-Net по скорости и не уступающая по качеству предсказания. Одним из ключевых аспектов предложенной архитектуры является использование предобученного энкодера, что позволило значительно сократить количество обучаемых параметров (1 243 944 настраиваемых параметров и 60 МБ места на жёстком диске) и улучшить качество извлекаемых признаков. Это решение обеспечивает более эффективную генерализацию модели, поскольку обученный на 14 000 000 картинок (на датасете ImageNet) энкодер способен извлекать множество различных признаков, отвечающих как за простые (волнистость, пятнистость, округлость и т.д.), так и за сложные структуры (очертания животных или постройки). Далее, обучая на наших данных декодер, мы учим сеть использовать только те признаки, которые необходимы именно в нашей задаче для построения маски. Важно отметить, что в роли энкодера может быть использована любая нейронная сеть, способная эффективно извлекать признаки из изображений, что делает предложенную архитектуру гибкой и легко адаптируемой к различным типам данных и задач.
В качестве функции активации в свёрточных блоках использовалась кусочно-линейная функция ReLU (Agarap, 2019), так как она менее затратна по вычислениям градиентов при обратном распространении ошибки (в отличие от сигмоиды и гиперболического тангенса, которые относятся к классу экспоненциальных функций). Также она более выразительна, чем логистический сигмоид. Для контроля качества обучения и сравнения результатов использовались метрики задачи семантической сегментации: матрицы ошибок (confusion matrix), Intersection over Union (IoU) (Rahman, Wang, 2016; Yu et al., 2022) и точность (Accuracy или Acc). Они позволяют количественно оценить степень совпадения выделенных объектов с размеченными. Данные метрики можно выразить через TP, FP и FN – количества истинно положительных, ложно положительных и ложно отрицательных срабатываний соответственно:
![]() ,
,
![]() .
.
Результат применения настоящей методики к фрагменту изображения микроимиджера из валидационной выборки представлен на рис. 3. Размеченная маска показана на рис. 3 B, предсказанная сетью бинарная маска на рис. 3 C. Была получена вероятностная карта маски (рис. 3 D), на которой пикселям присвоены значения в диапазоне от 0 до 1 – вероятности принадлежности пикселя фону и объекту соответственно. Помимо этого, представлены матрицы ошибок (рис. 3 E), которые показывают долю верно предсказанных масочных и фоновых пикселей, а также долю ложноположительных и ложноотрицательных срабатываний. Значения Acc и IoU на валидационном наборе данных составили 92% и 85% соответственно.
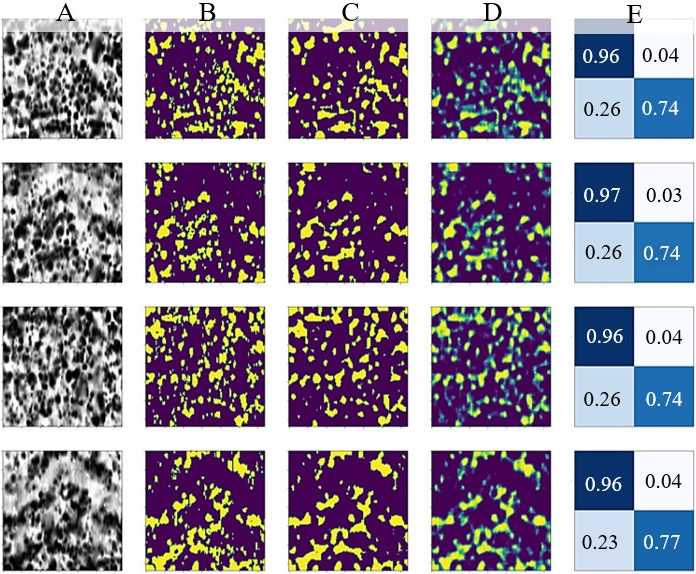
Рис. 3. Пример результата работы сети на фрагменте изображения имиджа
Свёрточная сеть в процессе сегментации основывается на анализе текстурных (например, пятнистости, шероховатости поверхности) и цветовых (например, интенсивности, яркости) характеристик геометрических признаков объектов, их взаимного расположения в пространстве, а также контекстуальных взаимосвязей с окружающими элементами. Такой подход позволяет эффективно выделять и классифицировать различные структуры с учётом их морфологических особенностей и в дальнейшем проводить их количественный и качественный анализ. На рис. 4 представлен пример выделенных объектов. В данном случае сеть обучена для распознавания пятнистых текстур, она адаптирована для выделения этих паттернов и игнорирует другие объекты, например, линейные и вытянутые структуры.

Рис. 4. Пример выделения пятнистой текстуры. Обозначения: A – имидж, B – имидж с наложенной размеченной маской, C – размеченная маска, D – результат сегментации сетью, E – ошибка детекции (разница между размеченными и предсказанными объектами), F – вероятностная карта, G – точность детекции.
Сегментация глубокой свёрточной сетью дает возможность получить количественную характеристику размеров, форм, ориентаций и топологии объектов (рис. 4 D). С помощью алгоритмов компьютерного зрения (Bradski, 2000) можно оценить изменение форменных параметров по глубине вдоль интервала исследования. К размерам относятся площади, периметры объектов и их выпуклых оболочек. Форма описывается округлостью, удлинением (aspect ratio), выпуклостью (отношение площади объекта к площади выпуклой оболочки) и т.д. К топологическим характеристикам относятся количество объектов и число отверстий в них. Ориентации объекта соответствует угол наклона его наибольшей оси.
Перечисленные характеристики заносятся в таблицу (рис. 5). Следует отметить, что формы отображения вычисленных количественных характеристик могут быть самыми разнообразными: от классической табличной формы (рис. 5) и точечного представления параметров на планшете по глубине (рис. 6) до отображения свойства на имидже и контурного представления целевых объектов. Форма отображения и оцениваемые форменные параметры определяются целями и задачами интерпретации имиджа.
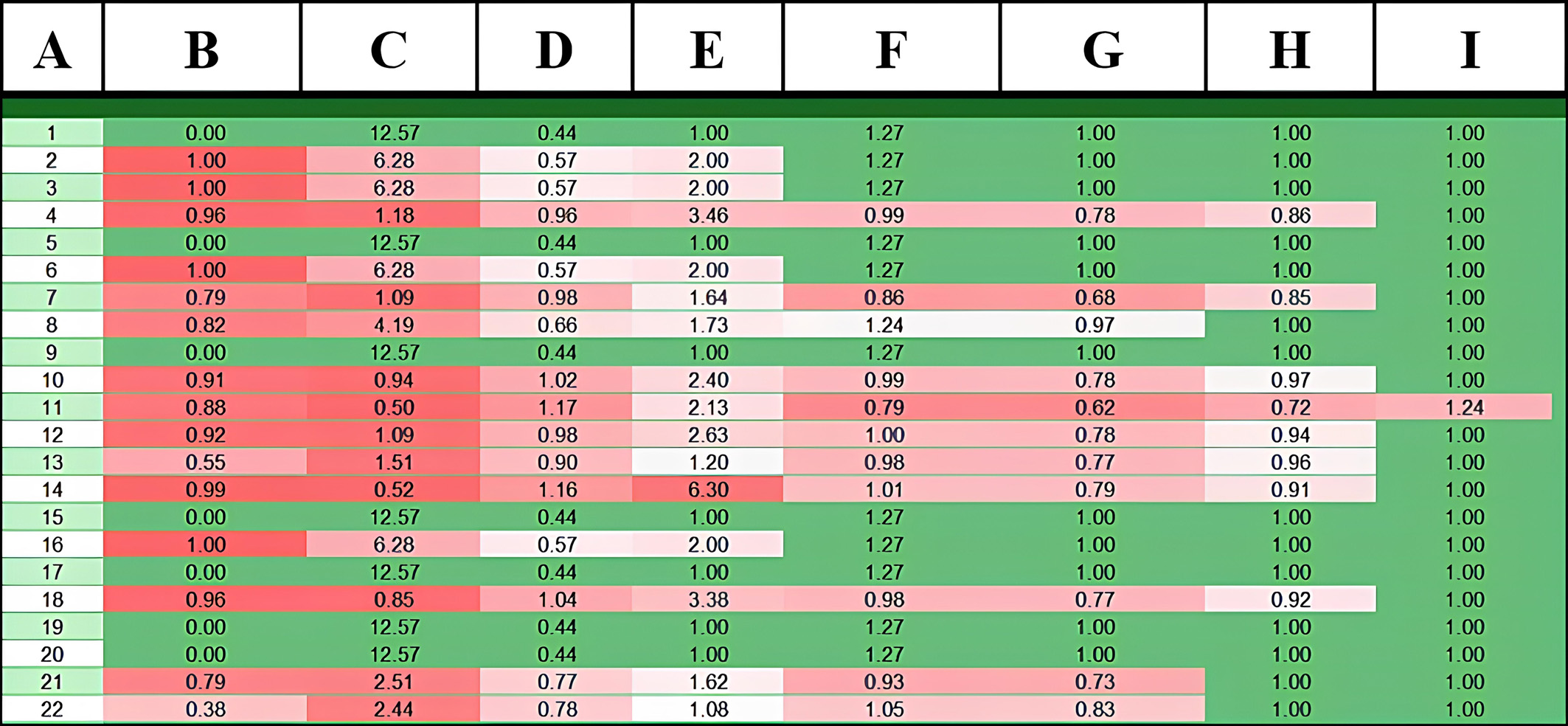
Рис. 5. Табличный формат представления результатов оценки форменных параметров целевого класса объекта. Обозначения: A – номер объекта, B – эксцентриситет, C – компактность, D – округлость, E – удлинение, F – эллиптичность, G – коэффициент прямоугольности, H – целостность, I – извилистость.

Рис. 6. Точечный каротажный формат представления результатов оценки форменных параметров целевого класса объекта. Обозначения: A – площадь, B – периметр, C – длина, D – ширина, E – ориентировка, F – положение по оси ординат.
В зависимости от практических требований характеристики объектов могут быть представлены в виде гистограмм, привязанных к глубине имиджей.
На рис. 7 показаны примеры имиджей с объектами, закрашенными в соответствии с их характеристиками. Для каждой характеристики (площади, периметра, длины, ширины и т.д.) подобрана цветовая палитра, учитывающая её распределение. Полученные таким образом визуализации позволяют анализировать распределения характеристик одновременно по глубине и углу развертки имиджа.
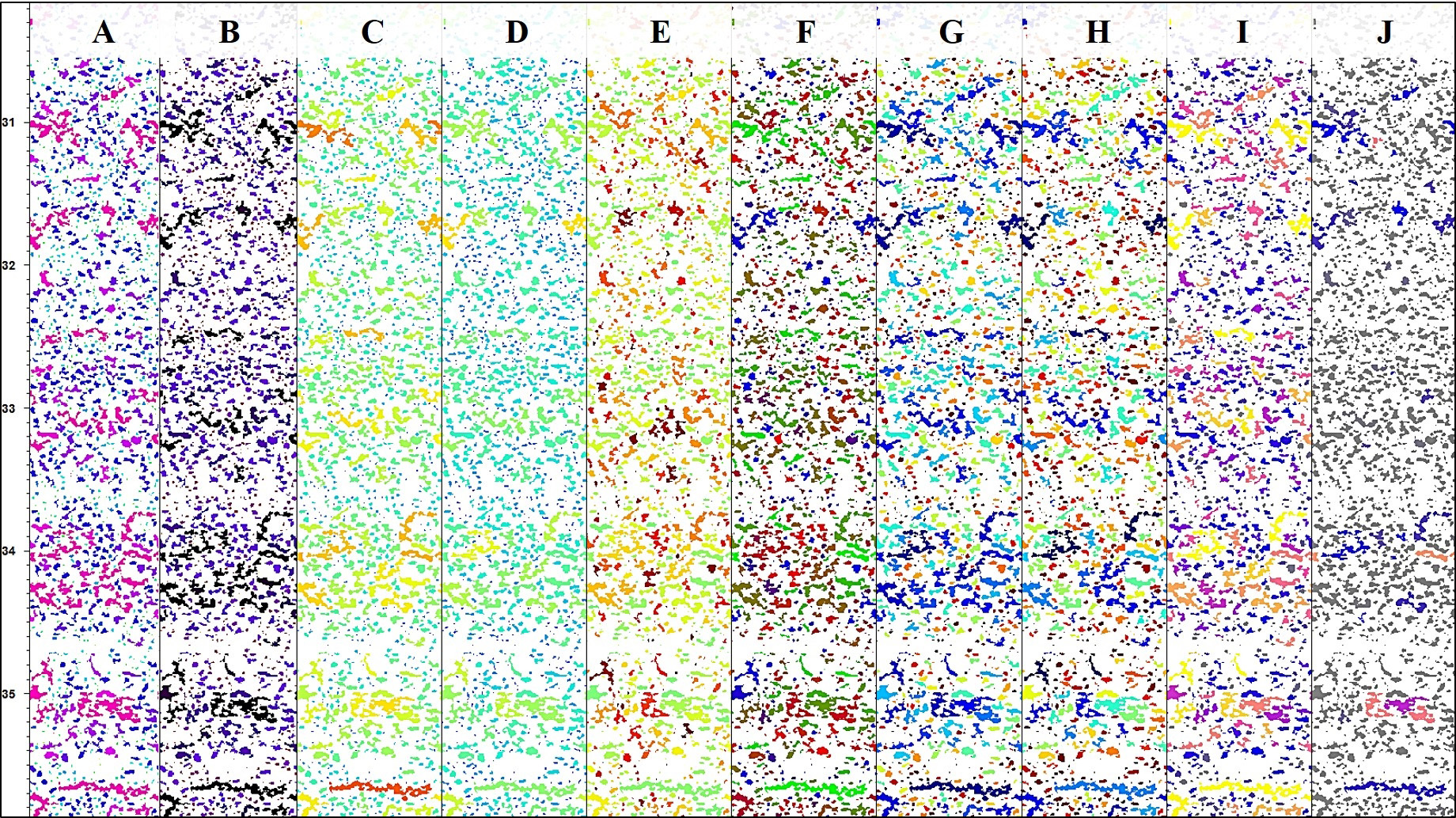
Рис. 7. Закрашивание объектов в соответствии со значениями характеристик. Обозначения: A – площадь, B – периметр, C – длина, D – ширина, E – ориентировка, F – эксцентриситет, G – компактность, H – эллиптичность, I – целостность, J – пустотность.
Для упрощения восприятия имиджей, присутствующие на них объекты могут быть заменены на оконтуривающие их эллипсы и выпуклые оболочки. На рис. 8 показаны такие контурные представления. На полученные изображения наложены оси и центры масс объектов.
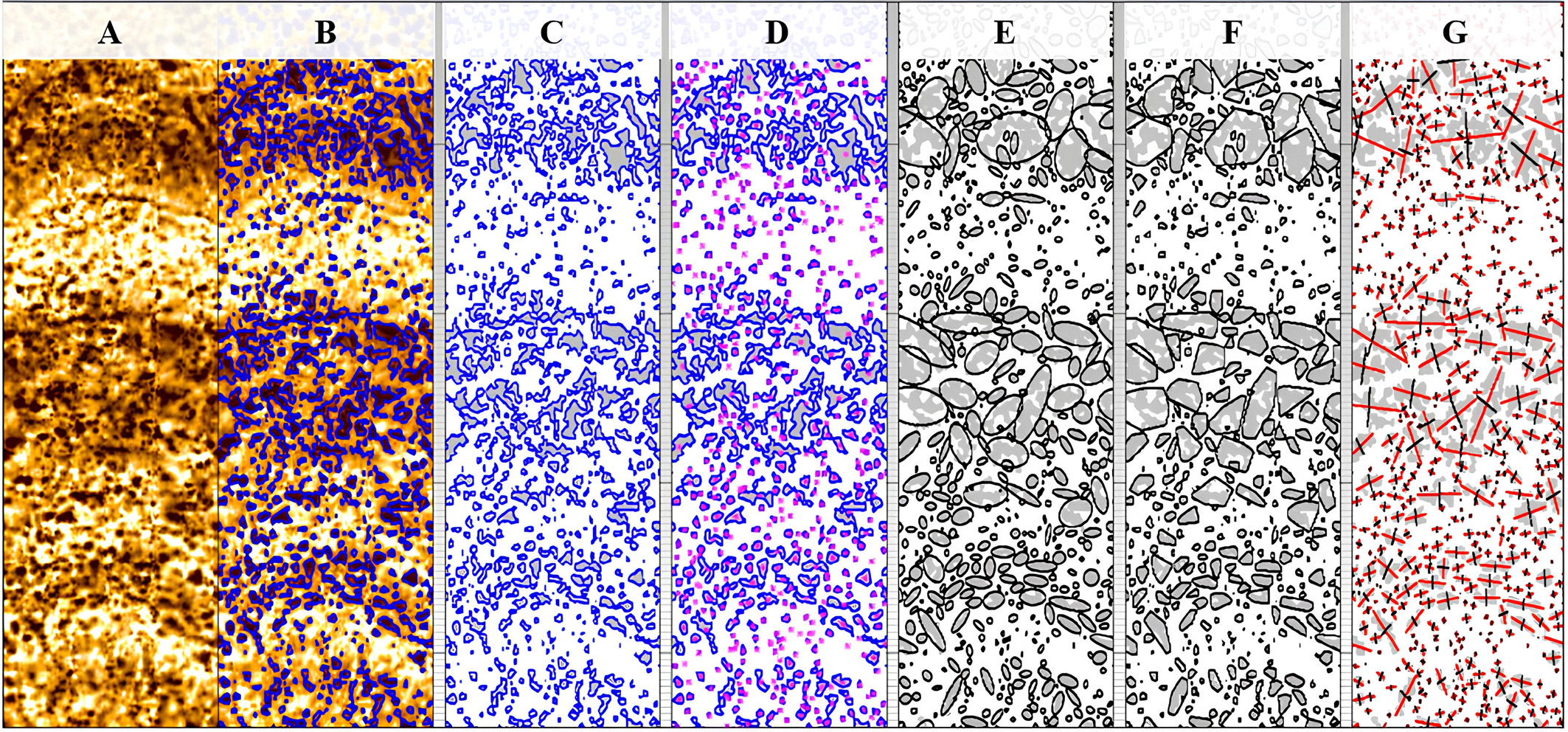
Рис. 8. Контурный формат представления объектов. Обозначения: A – исходный имидж, B – имидж с наложенными контурами объектов, C – контуры выделенных объектов, D – контуры и центры масс объектов, E – объекты, оконтуренные эллипсами, F – объекты, оконтуренные многоугольниками, G – большие и малые оси эллипсов.
Внутренние представления (шаблоны), изученные свёрточными нейронными сетями, легко визуализируются благодаря их соответствию зрительным образам. В настоящее время в литературе представлено несколько способов визуализации и интерпретации этих шаблонов (Chollet, 2021), которые можно разделить на следующие группы:
Так как наша задача – это задача семантической сегментации, то в качестве методов визуализации были выбраны визуализация фильтров и промежуточных выводов сети (карт активаций). С помощью визуализации фильтров можно получить набор характерных шаблонов, которые научилась выделять сеть в процессе обучения.
Визуализация самих весов свёрточных фильтров и их дальнейшая интерпретация (как было показано в (Köpüklü et al., 2019)) не всегда возможна, так как зачастую свёрточные фильтры имеют небольшой размер: например, 3х3 или 2х2 пикселя. Другой подход к исследованию фильтров, отвечающих за свёртки в нейронной сети, заключается в визуализации паттернов или шаблонов, выделяемых каждым конкретным фильтром. Это достигается с помощью метода градиентного восхождения (gradient ascent in input space). Суть метода состоит в том, чтобы применять градиентный спуск к входному изображению с целью максимизации отклика заданного фильтра. Начав с изображения, инициализированного случайными значениями, в процессе оптимизации значения пикселей изменяются таким образом, чтобы активация конкретного фильтра была максимальной. Для этого функция потерь должна максимизировать значение определённого фильтра на заданном свёрточном слое. Затем, с использованием метода оптимизации ADAM (Kingma, Ba, 2017), настраиваются значения входного изображения до получения результата: картинки шаблонов, которая максимизирует отклик исследуемого фильтра (рис. 9).

Рис. 9. Пример шаблонов, которые активируют определённый фильтр в слое. Обозначения: A – 14 фильтр 2 слой, B – 57 фильтр 3 слой, C – 60 фильтр 9 слой, D – 281 фильтр 24 слой.
Например, 14 фильтр 2 слоя (рис. 9 A) отвечает за выделение вертикально ориентированных линейных структур, 57 фильтр 3 слоя (рис. 9 B) – за выделение горизонтальных связных структур, 60 фильтр 9 слоя (рис. 9 C) реагирует на пятнистость, а 281 фильтр 24 слоя (рис. 9 D) уже отвечает за сложные волнистые объекты. Получаем, что с углублением сети (увеличением числа слоёв) фильтры выделяют всё более и более сложные паттерны, т.е. сеть обобщает всё более сложные объекты. Информацию о свёрточных фильтрах можно использовать для нескольких целей: для контроля «степени обученности» сети, для поиска характерных (уникальных) наборов текстур и для поиска похожих текстур и объектов. Если данных для обучения всех весов сети недостаточно и наступил эффект переобучения, то большинство фильтров или представляют собой случайный шум, или выделяют схожие паттерны. Характерные (уникальные) наборы текстур можно получить с помощью визуализации каждого фильтра в каждом слое и объединения похожих паттернов в группы. Для поиска похожих текстур необходимо выяснить, какой фильтр максимально активируется в сети для данной текстуры, и затем получить значение активаций данного фильтра для остальных текстур. Похожие текстуры будут иметь схожую величину активации.
На рис. 10 A показан пример характерной текстуры, а также визуализация методом восходящего градиента двух фильтров, которые давали минимальную (рис. 10 B) и максимальную (рис. 10 C) карту активации (по сумме всех значений).

Рис. 10. Пример характерной текстуры и визуализация фильтров, отвечающих за минимальную и максимальную активацию. Обозначения: A – пример текстуры на имидже, B – фильтр, дающий минимальную активацию, C – фильтр, дающий максимальную активацию.
Видно, что слабее всех активируется фильтр, отвечающий за вертикальные линейные структуры, а сильнее всех – фильтр, отвечающий за волнистые, синусоидальные объекты. Получив номер этого фильтра, можно ожидать, что сильнее всего он будет реагировать на фотографии с доминирующими синусоидальными структурами.
В результате выполнения настоящей работы была разработана методика для автоматической интерпретации данных скважинных имиджеров, основанная на результатах обработки большого объёма накопленных данных с применением машинного обучения. Предложен комплексный подход, состоящий не только в выделении объектов, но и количественной их оценке. Разработанный на основе данного метода универсальный инструмент предназначен для генерации адаптивных моделей, способных работать с разнородными входными данными. Обученные нейросетевые модели значительно сократили время, затрачиваемое на интерпретацию данных имиджей. Важным преимуществом применения моделей машинного обучения является их гибкость и возможность оперативного дообучения. Это позволяет адаптировать модели для новых данных (включая вариации в разрешении, качестве, аппаратурных особенностях, а также вариации в географических и стратиграфических условиях) или изменяющихся условий и обеспечивает возможность одновременной обработки соседних скважин. Разработанные нами методы и алгоритмы интерпретации позволяют через автоматизированные комплексные решения оптимизировать существующие процессы структурно-текстурного анализа, а также обеспечивают получение новой пообъектной количественной характеристики (линейных размеров, форменных параметров и др.), которой до этого не было. Инструментарий на основе предлагаемой методики призван обеспечить:
Ключевым фактором, определяющим эффективность сегментации, является качество обучающих масок. Их формирование остаётся на усмотрение пользователя: маски могут быть созданы как на основе реальных данных, так и с использованием гибридного подхода, сочетающего синтетические данные (с варьируемым уровнем шума) с масками по фактическим данным
Массовая количественная оценка объектов на имиджах послужит началом изменения подходов к геологическому и петрофизическому моделированию месторождений за счет обеспечения новым объёмом данных. Это приведёт к использованию детерминированного подхода или обоснованному выбору критериев распределения для стохастического моделирования, а также к определению петрофизических параметров с высокой степенью достоверности. Полученные данные окажут влияние на оптимизацию операционных задач недропользователя (например, программы по отбору керна) за счет быстрого и качественного решения части геологических задач с помощью имиджеров.
В рамках следующих этапов планируется разработка методики прямого корреляционного сопоставления результатов интерпретации имиджей с данными других геофизических методов. На сегодняшний день отсутствие такой методики обусловлено фундаментальными различиями в:
Разработка описываемого метода преследует в том числе цель решения указанной проблемы комплексирования. При этом ключевое преимущество метода заключается в его способности преобразовывать качественную визуальную информацию в количественные параметры, в перспективе сопоставимые с традиционными геофизическими измерениями.
1. Agarap A.F. (2019). Deep Learning using Rectified Linear Units (ReLU). ArXiv preprint arXiv:1803.08375. https://doi.org/10.48550/arXiv.1803.08375
2. Azim R.A. (2021). Estimation of fracture network properties from FMI and conventional well logs data using artificial neural network. Upstream Oil and Gas Technology, 7, 100044. https://doi.org/10.1016/j.upstre.2021.100044
3. Bradski G. (2000). The opencv library. Dr. Dobb’s Journal: Software Tools for the Professional Programmer, 25, pp. 120–123.
4. Canny J. (1986). A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence, pp. 679–698. https://doi.org/10.1109/TPAMI.1986.4767851
5. Chang Li, Liqiang Sima, Guoqiong Che, Wang Liang, Anjiang Shen, Qingxin Guo, Bing Xie (2020). Vug and fracture characterization and gas production prediction by fractals: Carbonate reservoir of the Longwangmiao Formation in the Moxi-Gaoshiti area, Sichuan Basin. Interpretation, 8(3), pp. 159–171. https://doi.org/10.1190/INT-2019-0260.1
6. Chen T., Guestrin C. (2016). XGBoost: A Scalable Tree Boosting System. The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, San Francisco California USA, pp. 785–794. https://doi.org/10.1145/2939672.2939785
7. Chollet F. (2021). Deep learning with Python. Simon and Schuster, 478 p. Cortes C. (1995). Support-Vector Networks. Machine Learning, 20, pp. 273–297. https://doi.org/10.1023/A:1022627411411
8. De Ville B. (2013). Decision trees. WIREs Computational Stats, 5, pp. 448–455. https://doi.org/10.1002/wics.1278
9. Fathi, E., Carr, T.R., Faiq, M.A., Panetta, B., Kumar, A., Carney, B.J. (2022). High-quality fracture network mapping using high frequency logging while drilling (LWD) data: MSEEL case study. Machine Learning with Applications, 10, pp. 100421. https://doi.org/10.1016/j.mlwa.2022.100421
10. Fix E. (1985). Discriminatory analysis: nonparametric discrimination, consistency properties. USAF school of Aviation Medicine.
11. Freund Y., Schapire R.E. (1995). A desicion-theoretic generalization of on-line learning and an application to boosting, in: Vitányi, P. (Ed.), Computational Learning Theory, Lecture Notes in Computer Science. Springer Berlin Heidelberg, Berlin, Heidelberg, pp. 23–37. https://doi.org/10.1007/3-540-59119-2_166
12. Friedman J.H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, pp. 1189–1232. https://doi.org/10.1214/aos/1013203451
13. Gabor D. (1946). Theory of communication. Part 1: The analysis of information. Journal of the Institution of Electrical Engineers - Part III: Radio and Communication Engineering, 93, pp. 429–441. https://doi.org/10.1049/ji-3-2.1946.0074
14. Geurts P., Ernst D., Wehenkel L. (2006). Extremely randomized trees. Mach Learn, 63, pp. 3–42. https://doi.org/10.1007/s10994-006-6226-1
15. Hilt D.E., Seegrist D.W. (1977). Ridge, a computer program for calculating ridge regression estimates. Department of Agriculture, Forest Service, Northeastern Forest Experiment. https://doi.org/10.5962/bhl.title.68934
16. John G.H., Langley P. (2013). Estimating Continuous Distributions in Bayesian Classifiers. arXiv preprint arXiv:1302.4964. https://doi.org/10.48550/arXiv.1302.4964
17. Kharitontseva P., Gardiner A., Tugarova M., Chernov D., Maksimova E., Churochkin C., Rukavishnikov V. (2021). An Integrated Approach for Formation Micro-Image Rock Typing Based on Petrography Data: A Case Study in Shallow Marine Carbonates. Geosciences, 11(6), pp. 235. https://doi.org/10.3390/geosciences11060235
18. Kingma D.P., Ba J. (2017). Adam: A Method for Stochastic Optimization. https://doi.org/10.48550/arXiv.1412.6980
19. Kohonen T. (2013). Essentials of the self-organizing map. Neural Networks, 37, pp. 52–65. https://doi.org/10.1016/j.neunet.2012.09.018
20. Köpüklü O., Babaee M., Hörmann S., Rigoll G. (2019). Convolutional Neural Networks with Layer Reuse. https://doi.org/10.48550/arXiv.1901.09615
21. Li, X., Shen, J., Zhu, Z., Wang, L., Li, Z. (2016). Fracture extraction from FMI based on multiscale mathematical morphology. SEG International Exposition and Annual Meeting, SEG-2016. https://doi.org/10.1190/segam2016-13880859.1
22. McCallum A., Nigam K. (1998). A comparison of event models for naive bayes text classification. AAAI-98 Workshop on Learning for Text Categorization. Madison, WI, pp. 41–48.
23. Mohammad Faiq Adenan, Fathi E., Carr T., Panetta B. (2023). Machine learning-based workflow for identifying fractures and baffles from Formation Micro Imager (FMI) log: A practical application in Illinois Basin Decatur Project (IBDP). SEG/AAPG International Meeting for Applied Geoscience & Energy. https://doi.org/10.1190/image2023-3916031.1
24. Otsu N. (1975). A threshold selection method from gray-level histograms. Automatica, 11, pp. 23–27.
25. Ponziani M., Slob E., Luthi, S., Bloemenkamp R., Le Nir, I. (2013). Fracture characterization from Formation MicroImager data. 75th EAGE Conference & Exhibition incorporating SPE EUROPEC 2013, European Association of Geoscientists & Engineers. https://doi.org/10.3997/2214-4609.20130805
26. Qifeng Sun, Naiyuan Su, Faming Gong, Qizhen Du. (2023). Blank Strip Filling for Logging Electrical Imaging Based on Multiscale Generative Adversarial Network. Processes, 11(6), 1709. https://doi.org/10.3390/pr11061709
27. Rahman M.A., Wang Y. (2016). Optimizing intersection-over-union in deep neural networks for image segmentation. The International symposium on visual computing. Springer, pp. 234–244. https://doi.org/10.1007/978-3-319-50835-1_22
28. Rennie J.D., Shih L., Teevan J., Karger D.R. (2003). Tackling the poor assumptions of naive bayes text classifiers. Proceedings of the 20th International Conference on Machine Learning (ICML-03), pp. 616–623.
29. Rigatti, S.J. (2017). Random forest. Journal of Insurance Medicine, 47, pp. 31–39. https://doi.org/10.17849/insm-47-01-31-39.1
30. Ronneberger O., Fischer P., Brox T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (Eds.). Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Lecture Notes in Computer Science. Springer International Publishing, Cham, pp. 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
31. Rosenblatt F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65, 386. https://doi.org/10.1037/h0042519
32. Sara U., Akter M., Uddin M.S. (2019). Image quality assessment through FSIM, SSIM, MSE and PSNR—a comparative study. Journal of Computer and Communications, 7, pp. 8–18. https://doi.org/10.4236/jcc.2019.73002
33. Shafiabadi M., Kamkar-Rouhani A., Riabi S.R.G., Kahoo A.R., Tokhmechi B. (2021). Identification of reservoir fractures on FMI image logs using Canny and Sobel edge detection algorithms. Oil & Gas Science and Technology–Revue d’IFP Energies nouvelles, 76, 10. https://doi.org/10.2516/ogst/2020086
34. Tahmasebi P. (2018). Multiple point statistics: a review. Handbook of mathematical geosciences: Fifty years of IAMG, pp. 613–643. https://doi.org/10.1007/978-3-319-78999-6_30
35. Tibshirani R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology, 58, pp. 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
36. Walker, S.H., Duncan, D.B. (1967). Estimation of the probability of an event as a function of several independent variables. Biometrika, 54, pp. 167–179. https://doi.org/10.1093/biomet/54.1-2.167
37. Ye S.-J., Rabiller P. (2000). A new tool for electro-facies analysis: multiresolution graph-based clustering. The SPWLA Annual Logging Symposium, SPWLA, SPWLA-2000.
38. Yu L., Li Z., Xu M., Gao Y., Luo J., Zhang J. (2022). Distribution-Aware Margin Calibration for Semantic Segmentation in Images. Int J Comput Vis, 130, pp. 95–110. https://doi.org/10.1007/s11263-021-01533-0
39. Zou H., Hastie T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology, 67, pp. 301–320. https://doi.org/10.1111/j.1467-9868.2005.00503.x
Георгий Андреевич Коссов – научный сотрудник
125171, Москва, Ленинградское ш., д. 16а, стр. 3
Владимир Викторович Абашкин – кандидат физ.-мат. наук, руководитель проектов
125171, Москва, Ленинградское ш., д. 16а, стр. 3
Сергей Сергеевич Егоров – технический руководитель группы геологической интерпретации данных
125171, Москва, Ленинградское ш., д. 16а, стр. 3
Дарья Олеговна Макиенко – научный сотрудник
125171, Москва, Ленинградское ш., д. 16а, стр. 3
Валерия Александровна Гаева – стажёр-исследователь
125171, Москва, Ленинградское ш., д. 16а, стр. 3
Коссов Г.А., Абашкин В.В., Егоров С.С., Макиенко Д.О., Гаева В.А. Новая методика текстурно-структурного анализа имиджей с помощью алгоритмов глубокого обучения. Георесурсы. 2025;27(3):209-220. https://doi.org/10.18599/grs.2025.3.22
Kossov G.A., Abashkin V.V., Egorov S.S., Makienko D.O., Gaeva V.A. A new state-of-the-art technique for textural and structural microimager data analysis using deep learning algorithms. Georesursy = Georesources. 2025;27(3):209-220. (In Russ.) https://doi.org/10.18599/grs.2025.3.22
Адрес редакции: Россия, 420087, Казань, ул. Аметьевская магистраль, д. 18, корп. 2, к. 3
Тел.: +79270390530, e-mail: mail@geors.ru
Издатель: ООО «Георесурсы»
Учредитель: Христофорова Д.А.











